.webp)
前回、前々回は音声認識されたテキストのセクシーじゃない作業である前処理とその効率化について書かせて頂きました。
今回は具体的なテキストマイニングの手法、“統計的な手法による特徴的なことばの抽出”について紹介をさせて頂きます。
それってホントに差があるの?
ことばの分析の前に、統計的な手法について説明します。
まずは次の問題を考えてみましょう。
【例題】
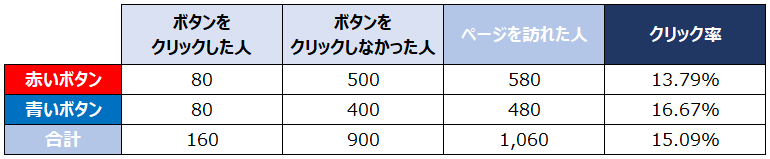
あるWEBサイトで『青いボタン』『赤いボタン』ではどちらがクリックされやすいかをそれぞれ3日間で検証したところ、次のような結果となりました。
『赤いボタン』の場合
ページを訪れた人:580人
ボタンをクリックした人:80人
クリック率 =(ボタンをクリックした人)÷(ページを訪れた人)= 80 ÷ 580 = 13.79%
ボタンをクリックしなかった人:500人(ページを訪れた人)-(ボタンをクリックした人)
『青いボタン』の場合
ページを訪れた人:480人
ボタンをクリックした人:80人
クリック率 =(ボタンをクリックした人)÷(ページを訪れた人)= 80 ÷ 480 = 16.67%
ボタンをクリックしなかった人:400人
となりましたが、ボタンの色を変えることによってクリックされやすくなると言えるでしょうか。
単純に考えるとクリック率に約3.0%の違いがあるため、青いボタンの方がクリックされやすいのではないかと考えられます。
ただ、この問題、前提条件に落とし穴があって、“3日間しか検証”がされていないデータなのです。
そのため、例えば別の3日間で検証をした場合には違う結果が出てくる可能性があり、今回のこの差が“たまたま起こったこと”なのかもしれません。
この “たまたま起こったこと” なのかどうかを統計的に調べる方法のことを、統計的仮説検定(以下、仮説検定)といいます。
仮説検定について
それでは上記の例題を「カイ二乗検定」という仮説検定を使って、“『青いボタン』と『赤いボタン』のクリック率に差があるかどうか” を判定していきしょう。
1.「ボタンの色に関わらず、ボタンを押した人の割合」を求める
今回の検証期間でのページを訪れた人(赤いボタン+青いボタン)の合計は1060人で、総クリック数(赤いボタン+青いボタン)は160回なので、クリック率は、
160クリック ÷ 1060人 = 15.09% です。
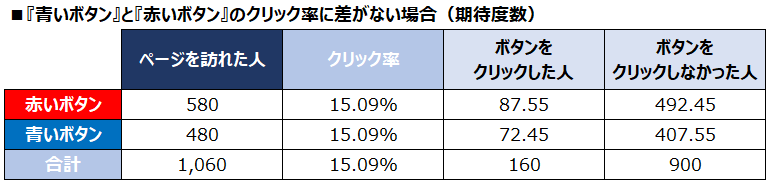
2.ボタンの色とクリックされやすさに関係がない場合の『青いボタン』と『赤いボタン』のクリック数を求める
もしもボタンの色とクリックされやすさに関係がないのなら、『青いボタン』でも『赤いボタン』でも「1.「ボタンの色に関わらず、ボタンを押した人の割合」を求める」で求めた15.09%のクリック率になるはずです。これを期待度数といい、『青いボタン』、『赤いボタン』の期待度数は次のように求められます。
『赤いボタン』
赤いボタンを押した人 = 580人(赤いボタンのページを訪れた人数)× 15.09% = 87.55人(期待度数)
ボタンを押さなかった人 = 580人(赤いボタンのページを訪れた人数)- 87.55人(期待度数)= 492.45人
『青いボタン』
青いボタンを押した人 = 480人(青いボタンのページを訪れた人数)× 15.09% = 72.45人(期待度数)
ボタンを押さなかった人 = 480人(青いボタンのページを訪れた人数)- 72.45人(期待度数)= 407.75人
クロス集計表にまとめると以下のようになります。
3.元のデータと期待度数との離れ度合いを求める
2の期待度数は『青いボタン』と『赤いボタン』のクリック率に差がない場合の値なので、元のデータが2の期待度数と近ければ近いほど、“『青いボタン』と『赤いボタン』のクリック率に差がある” ということが言えなくなります。
元のデータと期待度数が近いかどうかは、次の式を使って計算します。
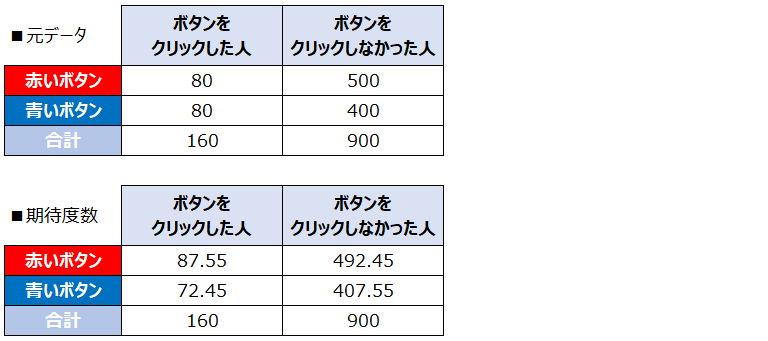
各項目の計算した結果は以下の通りです。

4.カイ二乗値を求める
上記の計算式で元のデータと期待度数の近さを計算したのは、カイ二乗値を算出するためです。
計算自体は簡単で、先ほどの表の中身を足し合わせるだけで計算できます。
0.65 + 0.79 + 0.12 + 0.14 = 1.65
5.カイ二乗値が大きいことの判断
結論から言うと、一般的なカイ二乗検定では、カイ二乗値が3.84より大きければ、“『青いボタン』と『赤いボタン』のクリック率に差がある” ということが言えます。
今回の場合は1.65ですので、“『青いボタン』と『赤いボタン』のクリック率に差があるとは言えない” ことになります。
-
※『カイ二乗検定』は、Excelでもこの検定をすることができ、以下の動画の解説がわかりやすいかと思います。
エクセルで「カイ二乗検定」が使えるようになる動画
特徴的なことばを抽出する
前置きが長くなりましたが、ここからが本題です。
上記のクロス集計と仮説検定を使った、“特徴的なことば” の抽出についてです。
次の表は架空のスマートフォンの修理受付窓口を想定し、昨日と一昨日の音声認識されたテキストに含まれる単語頻度を以下にまとめたとします。(簡単のために5つの単語に絞っています。)
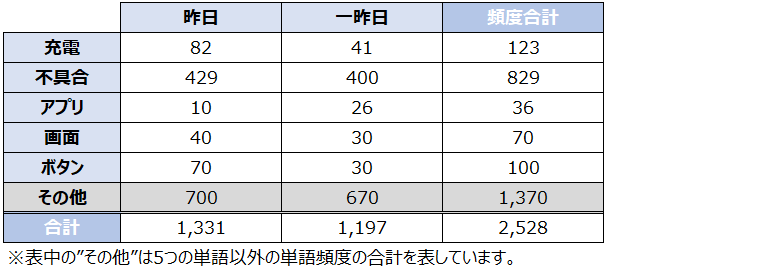
ここで、ある単語が昨日・一昨日とで比べて特徴的かどうかは、昨日・一昨日の出現率に有意に差があるかどうかを検定することで判断しています。
この出現率が先ほどの例題のクリック率にあたります。
ここでいう “単語の出現率” というのは、その日の単語の頻度割合を求めていきます。
例えば、昨日の『充電』の出現率は
(昨日の『充電』の頻度)÷(昨日の単語頻度の合計)
= 82回 ÷ 1331回
= 6.16%
と計算することができます。
5つの単語の昨日・一昨日の出現率を計算すると以下の通りです。
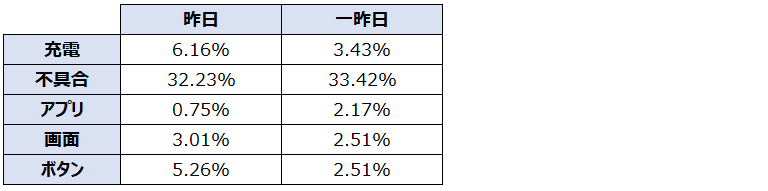
それでは、例として『充電』という単語が、昨日と一昨日を比較して特徴的なのか(昨日と一昨日の出現率に有意に差があるか)どうかは、以下のように『充電』という単語のみに着目した場合のクロス集計表に対して、『カイ二乗検定』を行うことで判定します。

ここでの『充電以外』の頻度は、昨日と一昨日の合計から『充電』の昨日と一昨日の頻度を引いた数値です。(例:昨日の『充電以外』の頻度 = 昨日の合計 - 昨日の『充電』の頻度)
このようにすることで、今問題にしたい『充電』という単語の昨日と一昨日の出現率にのみフォーカスを当てることができ、有意に差があるかどうかを判定することができるようになります。
他の4つの単語についても、同じようにクロス集計表にまとめて、上記の例題と同じようにカイ二乗値を求めると以下のようになります。
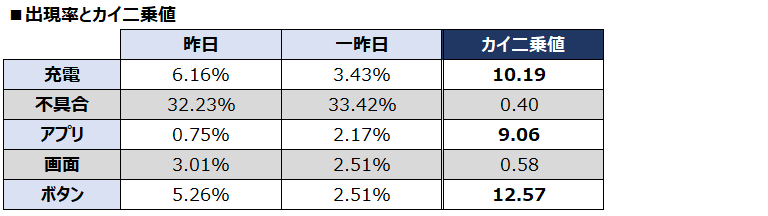
以上により、昨日と一昨日で比較すると、カイ二乗値が3.84より大きい、『充電』、『アプリ』、『ボタン』が特徴的であることが統計的に判定できました。
この特徴的なことばを使うことによって、“感覚的なものを客観的に判断できるようになる”可能性があります。
例えば、エスカレーションや応対を確認している中で、「なんとなく今日は○○の問い合わせが多い気がするな・・・?」という違和感を抱くことがあると思います。
特徴的なことばを確認することで、この違和感の裏付けが “定量的に、かつ客観的” に判断ができるようになります。また、逆に気づかなかったようなことを特徴的なことばから確認できるかもしれません。
特徴レポート
ここまで説明してきた、特徴的なことばをコールセンターのSVさんが定期的に見やすいようにするために、“特徴レポート”というサービスをリリースしています。
Omnia LINKで音声認識されたテキストを取得することで、毎日自動でレポートを取得できるサービスです。
今回は昨日と一昨日の単語頻度に着目した特徴的なことばの抽出について説明しましたが、
単語を集計する範囲を広げることで、
-
週ごとの特徴的なことば
-
月ごとの特徴的なことば
を抽出することができますし、時系列による抽出だけでなく、
-
オペレーターごとの特徴的なことば
も抽出することができます。
現状の課題に沿った、VOCアナリティクスのご用命をお待ちしております。
【参考URL】
ビーウィズでは、コンタクトセンターの応対テキストを分析する「VOCアナリティクス」サービスをご提供しております。
お客様のご要望(マーケティング活動の効率化・売上予測・コスト削減、等)に合わせて、企画立案・データ収集/分析・データ活用モデル構築・戦略立案まで一貫したサービスをご提供いたします。
ライター「nabe」の最新一覧
関連記事

前回は データ分析を任されたときに初めにぶつかる壁である「データのカテゴライズ」のうち、「既存の分類に当てはめる方法」について...

”分類”って得意ですか? - 私は苦手です。何を基準に”分類”すればいいか、悩んだ挙句、答えが出ない。そんなことが多くありませんか?...

さて、前回はVOCアナリティクスのセクシーじゃない作業と分析の流れを料理に例えながら紹介を致しました。今回は、データ分析のセクシ...

